- Published on
A short intro to retpolines
- Authors
- Name
- Vittorio Zaccaria
- @vzaccaria_en


In this post, I'll explore how speculative execution can be maliciously exploited through a technique known as branch target injection (BTI) and the mitigation (known as retpoline) currently used in the Linux kernel; this is a topic I wanted to cover during my course on Advanced Operating Systems but, for the lack of time, I was forced to leave it out. Let us start with the introduction of BTI by shedding light on the underlying architectural mechanism: CPU speculation.
A word about CPU speculation
Speculation in the context of CPU operation refers to the act of executing instructions before it is certain whether their execution is necessary or in the correct sequence. This is done to optimize the use of available resources and reduce idle time, especially when previous instructions involve waiting for data or resolving branches (the outcome of which may not be known until later in the execution pipeline).
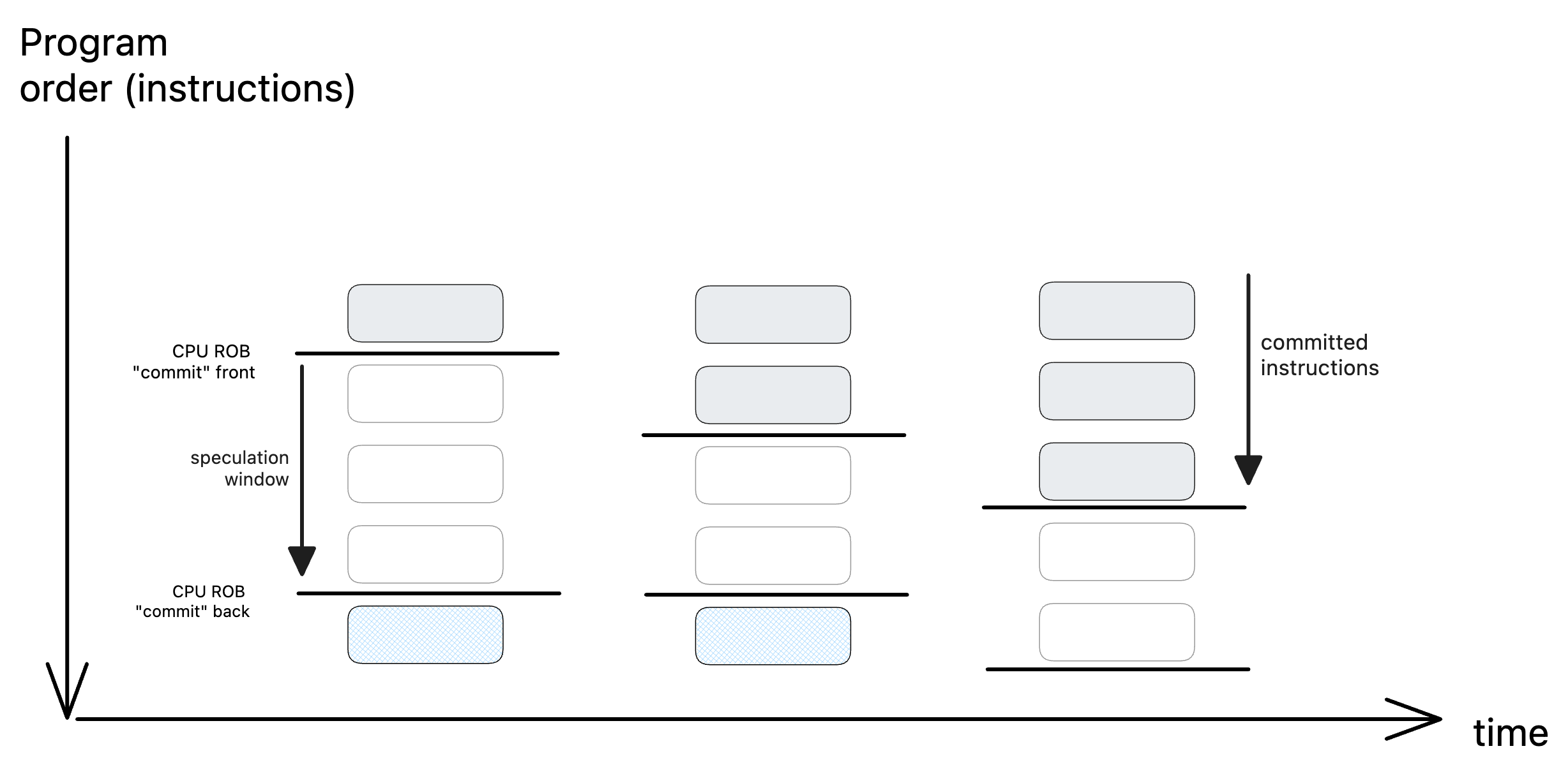
The Reorder Buffer (ROB) is a hardware feature that enables speculative execution and out-of-order execution while preserving the illusion of in-order completion. The commit front of the ROB is the point at which the instructions are considered to be non-speculative and can be safely committed in program order to the architectural state of the processor. Instructions to be considered for execution enter the ROB (or speculation window) from the back. Note, and this is very important, that these can enter the speculation window even if they are not necessarily executed by the normal program flow.
Spectre's branch target injection
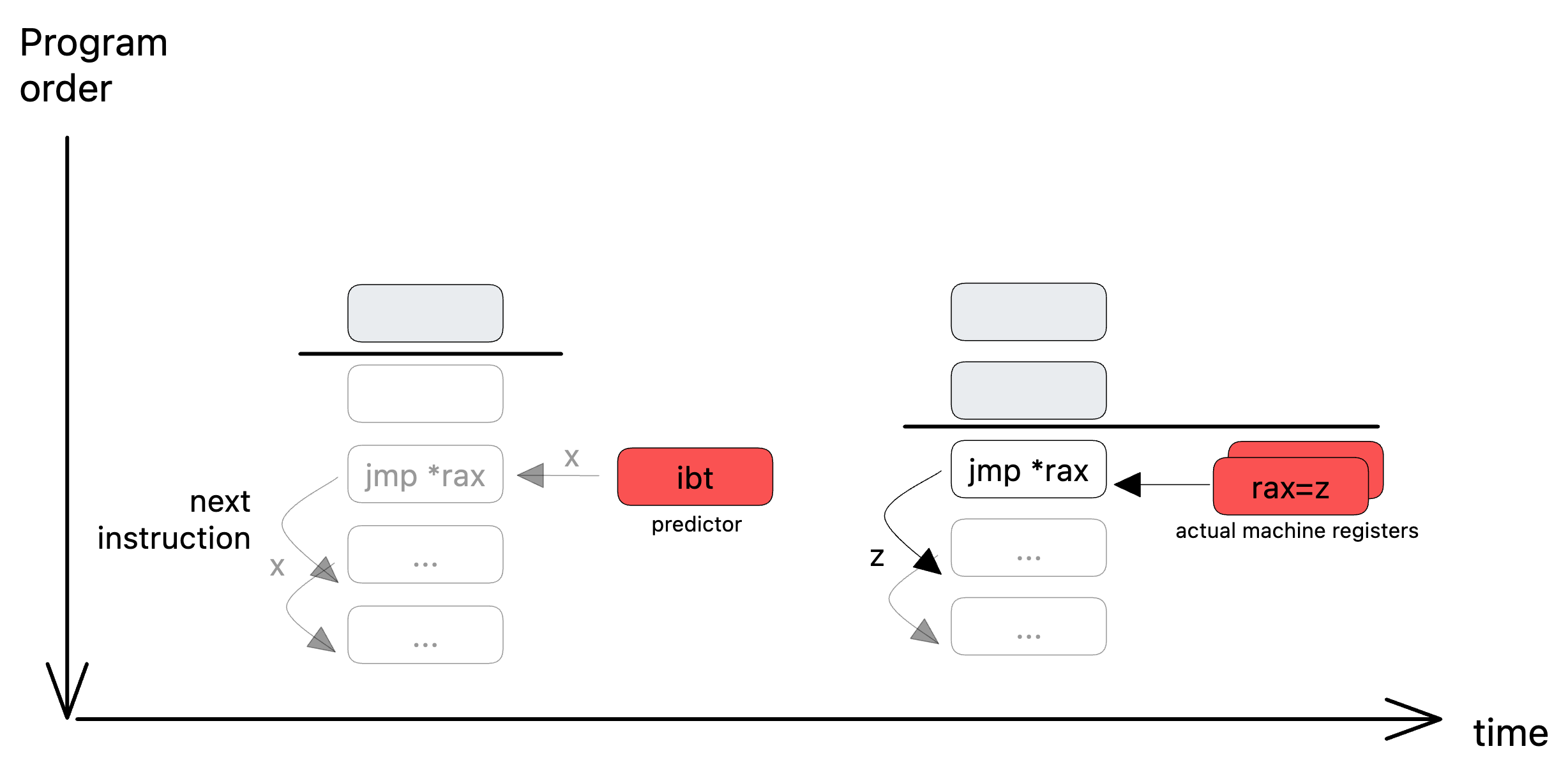
Branch target injection belongs to the class of attacks known as Spectre. BTI makes use of the speculative execution of indirect branches: during processor speculation (see picture below to the left), if an indirect branch enters the speculation window (in this case jump to index pointed by register %rax), it guesses the next instruction to be speculatively executed through an Indirect Branch Prediction Target (IBT) memory which provides the most likely address to branch to. Note that this is just a prediction as the value of rax is not known at that moment. This value is only known when all the previous instructions have been committed (or exited from the ROB), see picture below to the right:
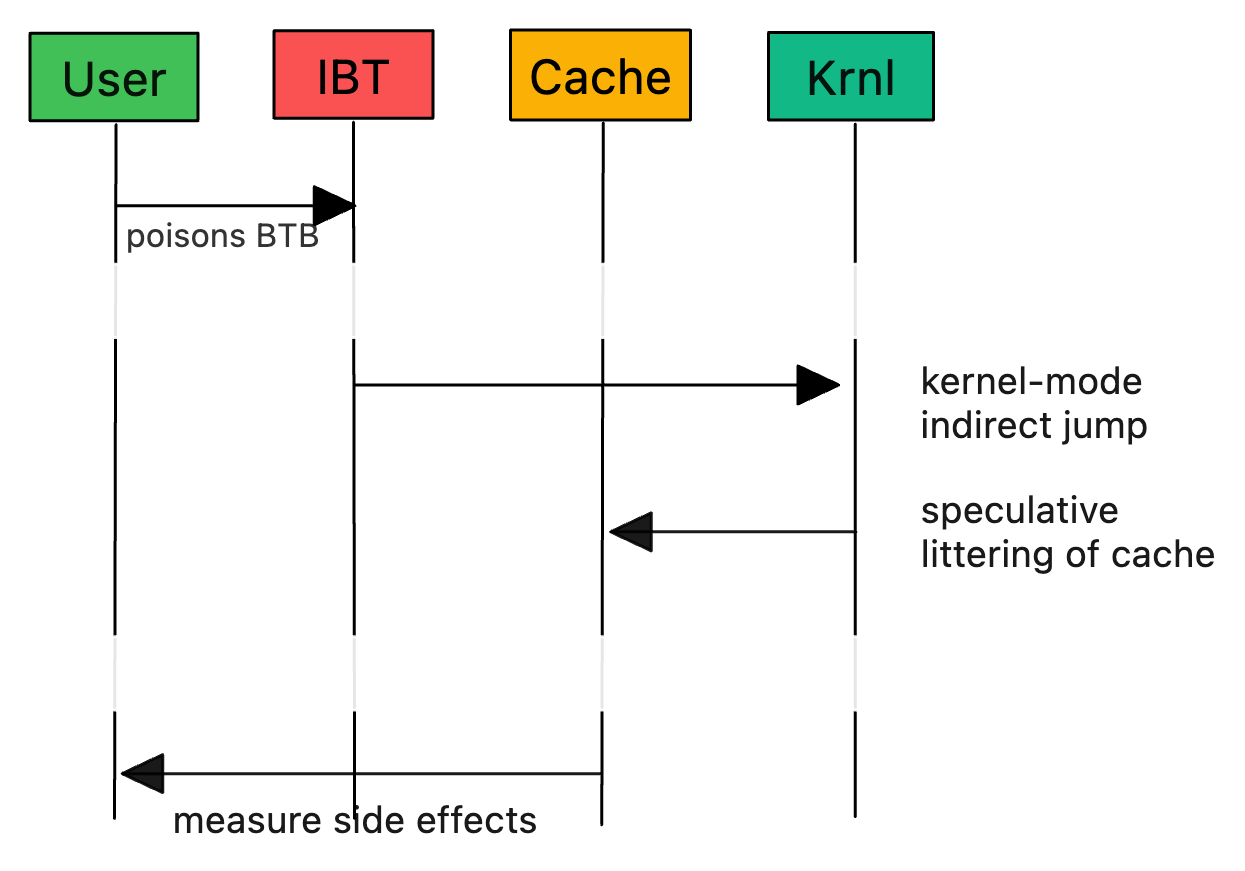
It turns out that this process can be poisoned by a hacker by forcing speculative execution from address x(instead of z). This is possible because the IBT can be primed by any program on the system1. And here’s where things get really interesting: the side-effects left in the processor's caches during this speculative execution can be measured and this is sufficient to make it leak data:
Retpolines to the rescue
A key observation is that we can implement indirect branches also as function return and that, unlike indirect branches, a different predictor, called return stack buffer (RSB), is used2.
"Retpolines" are just that; you substitute indirect jumps with function returns. One thing to note is that the hardware's cache for the return target (RSB) and the actual destination maintained on the stack are separate entities. The RSB entry is invisible to the underlying application, but we can manipulate its generation during speculative execution while tweaking the visible on-stack value for directing how the branch actually retires.
Here's the code of a trampoline substitute for jmp *rax:
call .a
.trap:
pause; lfence
jmp .trap
a:
mov rax, (rsp)
ret
To see how it works, let us first consider the non-speculated execution:
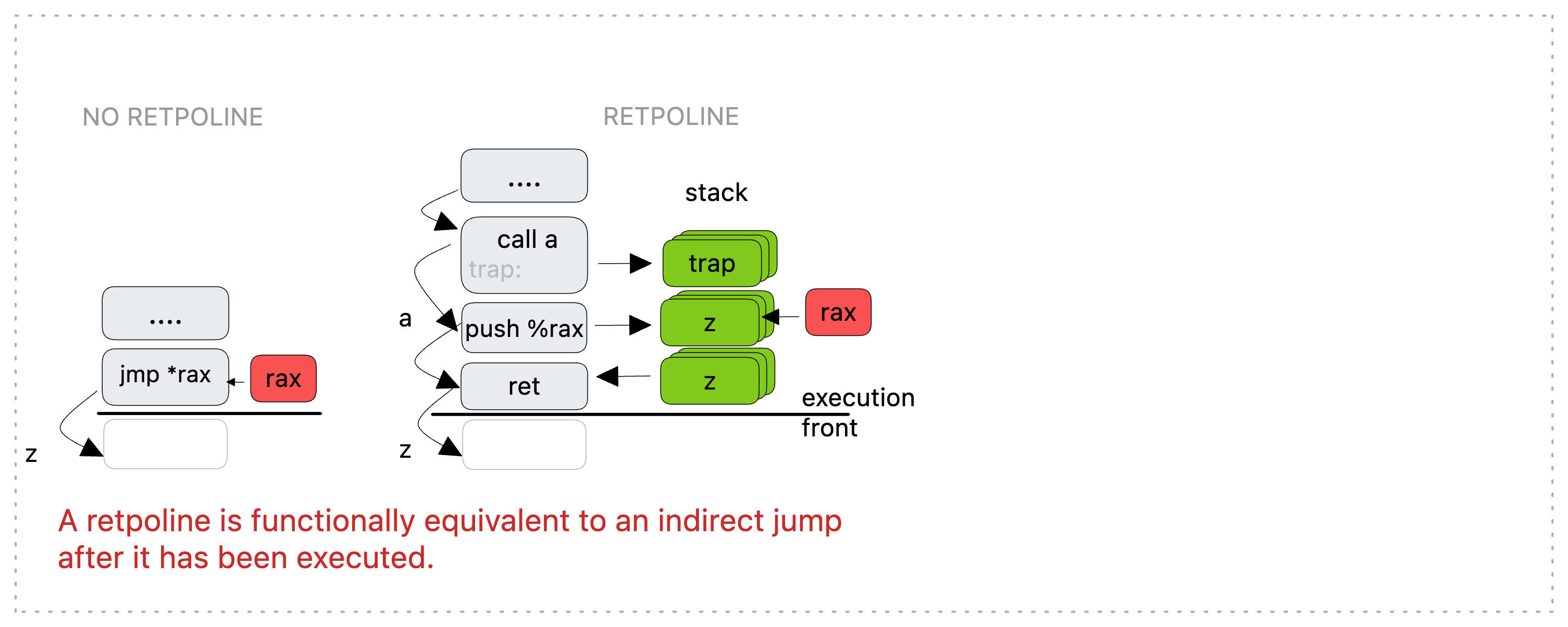
First, a direct 'call' is made to a. This is known at compile time and doesn't trigger speculative target resolution. It generates a stack entry with a return target of trap which is the label immediately after a. Next, we edit the on-stack entry generated by step one, directing it to %rax. Finally, we return against our original 'call' which uses correctly the value on the stack. And everything proves equal to the original indirect branch.
Let us now consider what happens during speculation (grey box on the right):
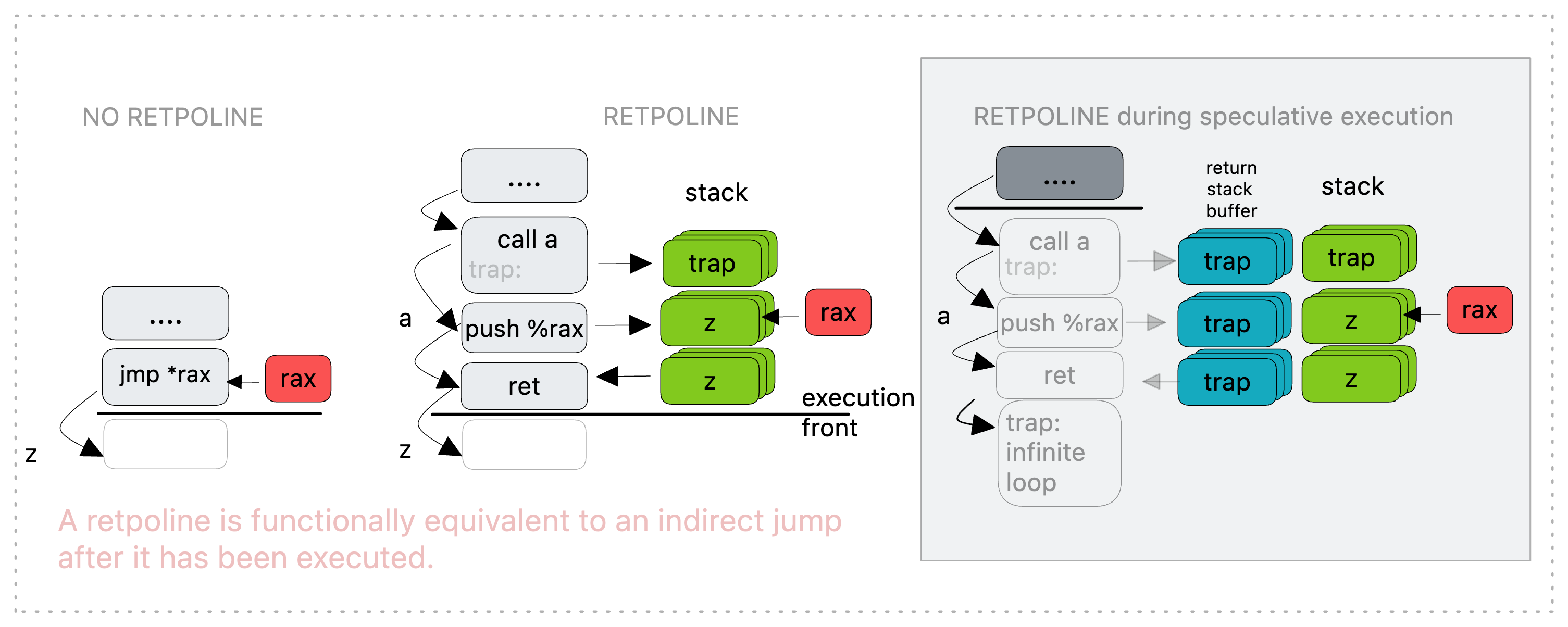
First, a direct 'call' is made to a. This is known at compile time and doesn't trigger speculative target resolution. It generates distinct stack and RSB entries with a return target of 'trap'. Next, we edit the on-stack entry generated by step one, directing it to %rax. This doesn’t affect the RSB entry from before which still targets 'trap'.
Finally, we return against our original 'call'. This time speculative execution consumes the RSB entry and gets caught within the pause loop at trap. These instructions are only executed by the speculative path. Once our return retires, the on-stack value locates the actual new instruction pointer and any harmless results of speculative execution in the loop at trap are dismissed.
Footnotes
On x86, this is due to the fact that all source addresses (i.e., the addresses of the branches) that have the same lower 12 bits resolve to the same target address. ↩
This kind of predictor is quite common in different forms like Intel's Return Stack Buffer or AMD's Return Address Stack or ARM's Return Stack. ↩